 开云官方
开云官方
从实验数据中发掘科学限定,这件事每天皆辞寰宇各地的实验室里献艺:筹商者们把不雅测效果整理成表格、画成弧线,凭直观和教育揣摸背后的函数姿色,再反复修正,最终得到一个既能拟合数据、又能长远机制的数学公式。不管是开普勒从第谷的不雅测数据中提真金不怕火出行星畅通定律,照旧现代工程师们每天进行着的各式标定,背后依赖的皆是这样的过程。
标记总结(Symbolic Regression)的想法,就是让计较机自动完成这种 “从数据到公式” 的发现。但这项任务遥远以清苦著称:候选公式的空间近乎无尽。即使加上大说话模子(LLM)的语义指挥,此前最佳的措施在面临最新基准 LLM-SRBench 的 129 个合成科学方程任务时,准确率也仅有 15%。
近期,来自博世中央筹商院与清华大学的筹商东谈主员提议 FunctionEvolve 框架,在两大基准测试上大幅刷新了这项任务的效果。在 LLM-SRBench 的 129 个合成科学方程任务上,FunctionEvolve 最终给出的公式在 55.8% 的任务上与真实公式等价(SA@1 = 72/129),是此前最佳效果的 3.6 倍;若将范围放宽至辗转最小的前 50 个公式,这一比例更是达到 82.9%(SA@50 = 107/129)。而在经典测试基准 AI-Feynman 的 120 个任务上,FunctionEvolve 则拿到了满分:SA@1 = 120/120,即最终给出的每一个公式皆正确。
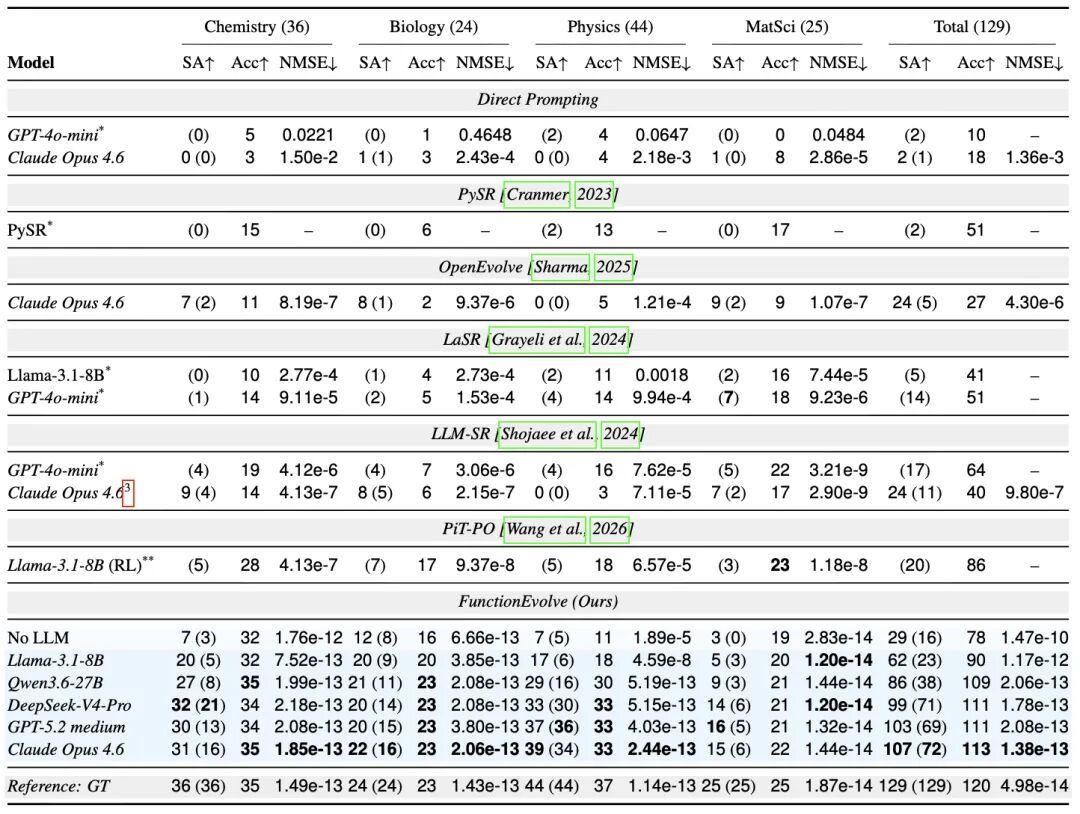
LLM-SRBench 129 个合成任务上的主效果:表中诠释 SA@50(括号内为 SA@1)、Acc0.1 任务数与测试集 NMSE 中位数;加粗为各列最优,ground-truth 行是行为参考上界的真实公式弘扬

论文标题:FunctionEvolve: Structure-Guided Symbolic Regression with LLMs
名堂地址:https://github.com/Phoinikas03/FunctionEvolve
论文链接:https://arxiv.org/abs/2606.07704
本文第一作家夏泽宇,是清华大学计较机系朱军教讲课题组的博士一年纪学生,筹商地点为 LLM 推理过甚科学应用。通信作家阎栋博士是博世首席 AI 科学家、前百川智能筹商留神东谈主,遥远从事 LLM 西席、推理和强化学习筹商。博世中央筹商院聚焦 LLM、AI4Science 等前沿地点,贫困于于买通从学术摧折到工业落地的全链路翻新,过去沿手艺赋能产业变革。
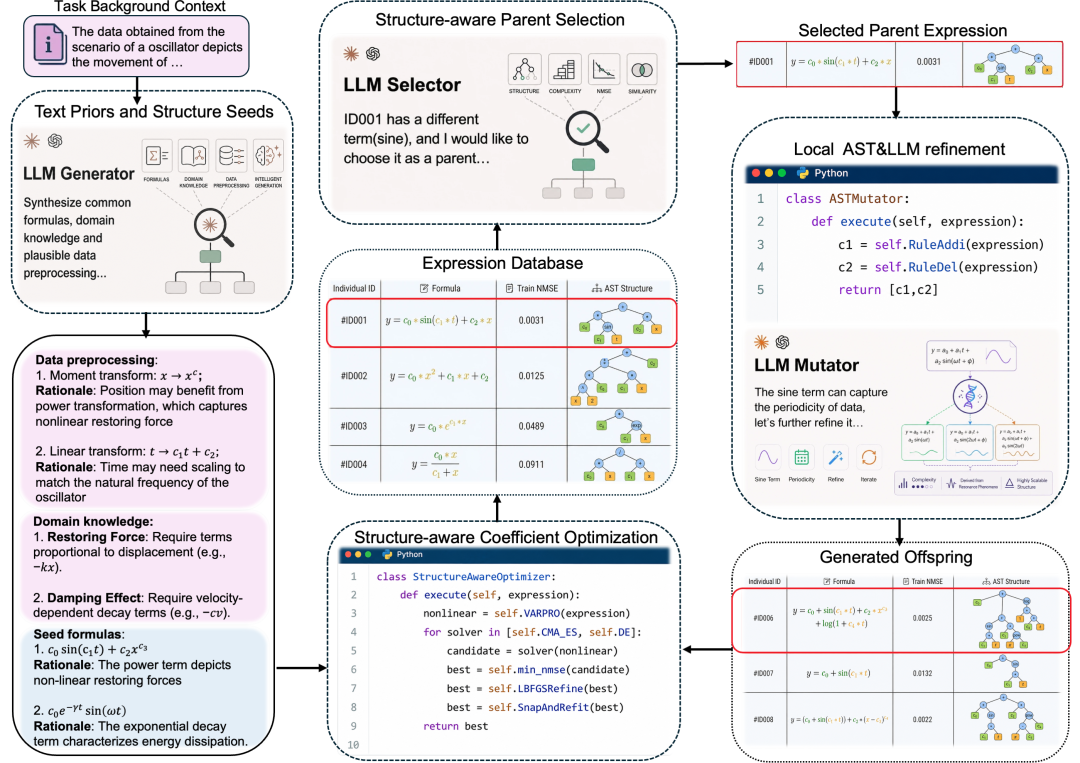
FunctionEvolve 总体进程:从任务布景中索求先验,生成种子公式,再通过结构信息指挥父本采取、AST 与 LLM 局部变异、结构分类的通盘优化等要津,捏续迭代候选抒发式
为什么要让公式沿结构进化
标记总结的难,最初难在问题自身:几个变量加上十几个运算符,能组合出的公式数目多到天文数字,逐个去试根底不本质。更要害的是,标记总结的想法从来不是 “把数据拟合准” 这样苟简。用冯・诺依曼的话说:“给我四个参数,我不错拟合出一头大象,而用五个参数我不错让它的鼻子舞动。” 它证明只须抒发式富余复杂,咱们简直总能构造出一个公式,把有限的数据点拟合的天衣无缝;但这仅仅记着了数据,而不是发现了限定。一朝输入范围发生变化,或者遭逢新的实验条目,这类公式的预计就可能赶快崩掉。因此,标记总结信得过清苦的地方,不仅仅从广泛公式空间里找到一个低辗转抒发式,而是在低辗转、精炼性、可诠释性和外推智商之间找到均衡。
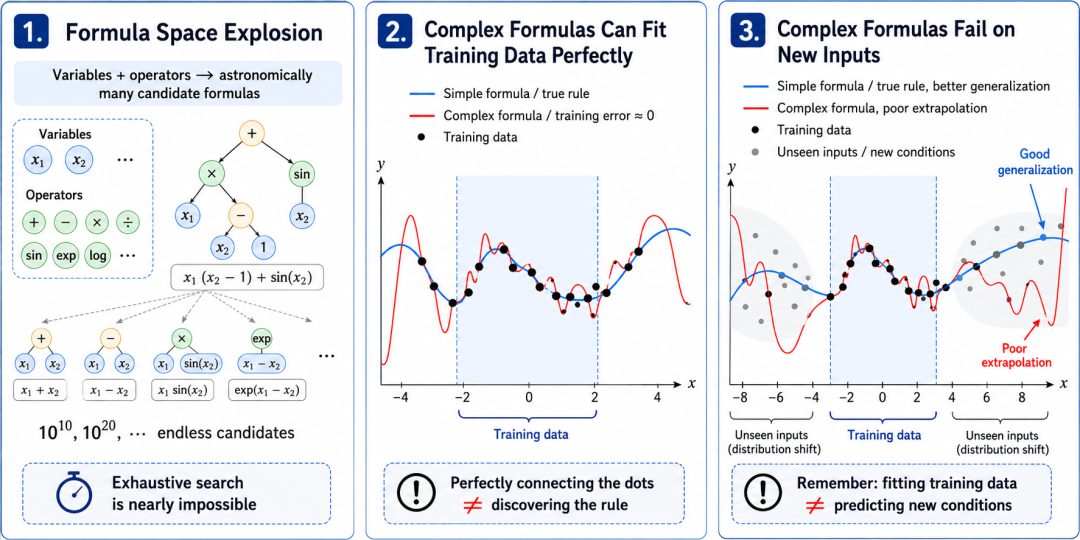
要把标记总结搜索从 “压低辗转” 引向 “找对限定”,就得用上界限学问。比如任务描摹里写着 “r 是两个带电粒子之间的距离”,那么平时反比项就比 r 的高次多项式更值得一试 —— 这种判断恰是 LLM 擅长的,它能读懂任务布景,把界限学问形成对公式姿色的建议。但这种语义判断必须落到可操作的公式语法上,身手信得过干涉搜索过程:相似是 “试试平时反比”,究竟该在现时公式里找到含 r 的哪一项替换?这就要求系统清澈公式由哪些部分构成、蜕变该落在哪。抒发式树 / 概括语法树(AST, Abstract Syntax Tree)提供的恰是这种语法姿色:它把公式拆成层级结构,公式由哪几部分构成、哪些部分值得保留、蜕变不错落在那处,皆一目了然。从 AST 的视角启航,传统 Genetic Programming(GP)有语法暗示,却清寒语义指挥,结构变异多是立时试探;而径直用 LLM 生成公式虽有语义地点,却清寒褂讪的语法拘谨,容易举座改写公式并碎裂已有子结构。
FunctionEvolve 的切入点,就是把公式显式暗示为抒发式树。它再行定位了 LLM 的参与姿色:系统看到的除了拟合辗转,还有公式的里面构造,每一步修改皆落在公式的一个子结构上。这棵树也贯串 FunctionEvolve 的每个要津:
生成最先(Generator):先由 LLM 证据任务布景写出一批种子公式,让搜索从贴合问题的最先启航;
采取地点(Selector):结构阁下的候选被归为一类,搜索预算优先分给结构上有各异的地点,幸免在统一类结构上反复打转;
局部变异(Mutator):LLM 提议的更正见地(比如 “把这一项换成平时反比”)被落实为抒发式树上的局部操作,幸免推倒重写或圣洁更动;
拟合与评分(Optimizer):结构定下来后,公式里的待定通盘还要靠数据调到最安妥。系统愚弄结构信息让这一步更可靠:线性叠加的通盘不错径直解出,毋庸参与搜索;剩下的通盘也能按所在位置压缩搜索范围,比如三角函数里的相位只需在一个周期内找。这显贵缩短了正确的公式姿色因为通盘没调好而被错判的风险。终末,系统还会认出写法不同、实则相通的候选,去掉重叠,再决定哪些公式干涉下一轮。
因此,FunctionEvolve 把 LLM 的语义指挥拘谨在抒发式树这套语法里,让生成、采取、变异和评分皆围绕结构张开。
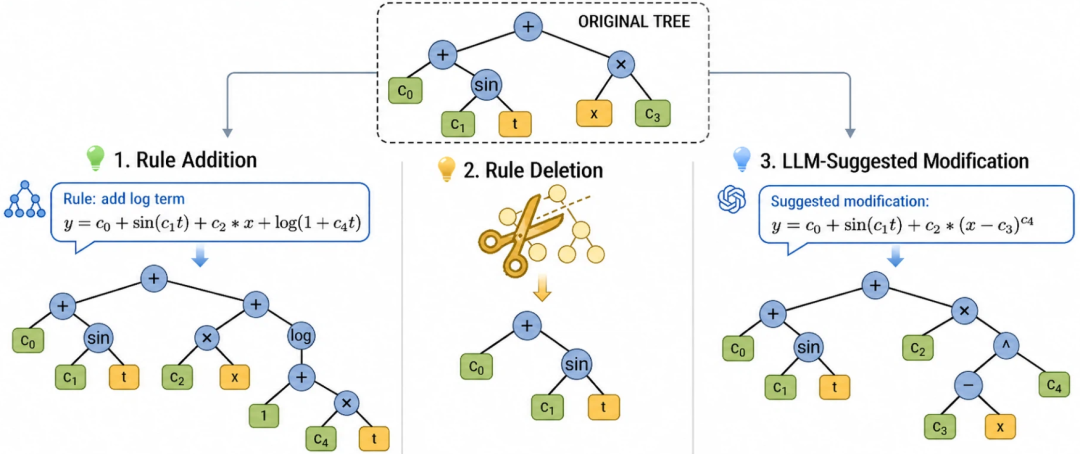
FunctionEvolve 在抒发式树上进行局部结构变异,使 LLM 的语义建议粗犷落到可控的子结构推广或替换上
主要效果:双基准考据
筹商团队采取了两个互补的基准来评估 FunctionEvolve。主要效果基于最新的 LLM-SRBench:它的 129 个科学方程任务袒护化学、生物、物理和材料科学四个界限,何况皆是东谈主工合成的,LLM 简直不行能在西席料念念中见过,因此更能覆按措施是否真的是在 “发现” 公式,照旧在背诵纪念。补充考据使用经典的 AI-Feynman:它的 120 个方程取自《费曼物理学教材》,从万有引力到电磁学,皆是物理学里真实的定律,遥远以来是标记总结措施的圭臬试金石,能覆按措施在真实科学公式上是否相似有用。
论文主要诠释三类目的。导语中出现的标记准确率 SA@k,它的界说是按西席数据上的归一化均方辗转(NMSE)排序后,前 k 个候选抒发式中是否出现与想法公式标记等价的效果。事实上,好多公式写法不同,但数学上是等价的,也就是本文说的 “正确公式”;SA@50 推敲了 FunctionEvolve 是否找到了谜底,SA@1 则推敲其能否把谜底排在首位。Acc (τ) 推敲首位候选公式在测试点上的最大相对辗转是否低于阈值 τ,因此 Acc (0.1) 暗示相对辗转低于 0.1 的任务数;测试集 NMSE 的中位数则响应举座数值拟合辗转,数值越低证明拟合越好。
LLM-SRBench:标记准确率 3.6 倍于此前最佳效果
在 LLM-SRBench 主实验中,对比最显豁地体面前公式的标记准确率上。使用相似的 Claude Opus 4.6 行为后端,此前列法 LLM-SR 与 OpenEvolve 的 SA@50 皆是 24/129,而 FunctionEvolve 栽种到 107/129;只看首位候选,FunctionEvolve 的 SA@1 也达到 72/129。换用 GPT-5.2 medium、DeepSeek-V4-Pro、Qwen3.6-27B 和 Llama-3.1-8B 测试,SA@50 仍分别达到 103、99、86 和 62。即就是开源的 8B 小模子,也远高于此前列法用强闭源模子取得的效果,证明栽种主要来自结构化 FunctionEvolve 框架自身,而非某个闭源模子。
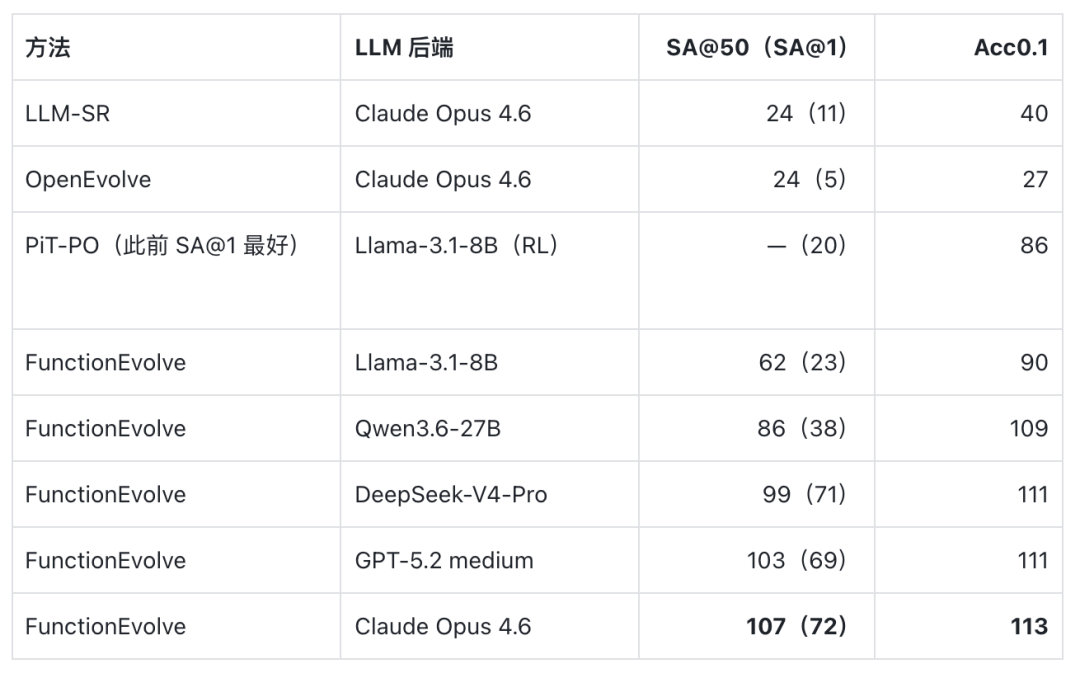
注:PiT-PO 原文只诠释了 top-1 效果,故无 SA@50;它是此前 SA@1 的最佳公开效果(20/129,约 15%),本文中的 "3.6 倍" 即以此为基准。
AI-Feynman:120/120 全射中,但要分裂 “背” 与 “推”
在补充考据的 AI-Feynman 上,FunctionEvolve 的 top-1 候选在沿途 120 个任务中射中正确公式;行为参照,此前的 SOTA 措施 QDSR 射中了 107 个。也就是说,不管面临合成方程照旧真什物理定律,FunctionEvolve 皆取得了迄今为止的最高准确率。不外,AI-Feynman 的公式来自经典物理教材,LLM 很可能在西席语料中见过。为覆按纪念的影响,筹商团队统计了每个任务中第一个正确公式出现的轮次:第 0 轮就射中,证明谜底也曾写在 LLM 生成的运行种子里,更像是 “背” 出来的;出面前后续轮次,则证明谜底来自搜索过程自身。下图的轮次分散流露,两个基准恰恰呈现出相背的步地:AI-Feynman 的正确公式汇集在第 0 轮,纪念的因素照实存在;而在不行能被背过的 LLM-SRBench 上,正确公式大多出面前后续轮次。这正证明,FunctionEvolve 并不是在调取 LLM 的纪念,而是把 LLM 放进了推理过程,让正确公式在一轮轮局部变异、通盘拟合和再行评分中渐渐被 “推” 出来。
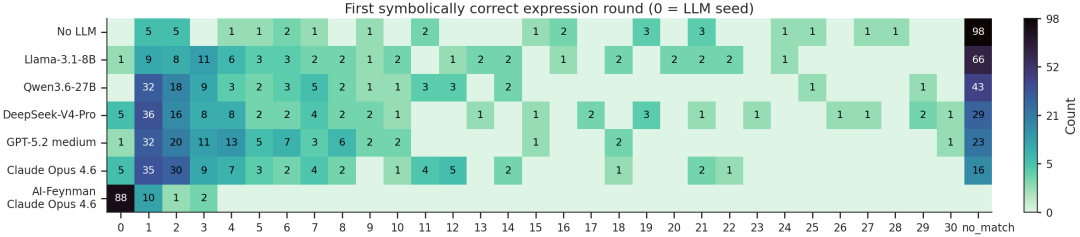
LLM-SRBench/AIFeynman 任务中第一个标记等价抒发式出现的轮次分散
分析实验:候选筛选与组件消融
除两个基准上的主效果外,论文还进行了两组分析:一组覆按最终候选的筛选政策,证明许多已被推出来的正确公式仅仅在排序阶段被挤出了首位;另一组通过系统消融,量化各组件对举座性能的孝顺。
正确公式常被挤出首位:让筛选偏好更苟简的公式
LLM-SRBench 的 129 个任务中,若看 SA@50 FunctionEvolve答对了 107 个,看 SA@1 则答对 72 个。这个差距揭示了另一个问题:推理过程常常也曾找到了正确公式,仅仅按西席 NMSE 排序时,它会被辗转更低的复杂类似式挤到背面。那么,在不动用测试集等荒谬信息的前提下,能否靠 “采取姿色更精炼的公式”把这些也曾找到的谜底筛出来?为覆按这少许,论文固定竣工搜索轨迹,不改变生成、变异和通盘优化过程,只在推理终了后比较三种基于西席辗转与抒发式复杂度的筛选决策:Pareto 保留在辗转和复杂度之间不行同期更正的候选,Occam 在辗转接近时优先采取更苟简的抒发式,MDL(Minimum Description Length)则把辗转和复杂度合并为一个总资本。
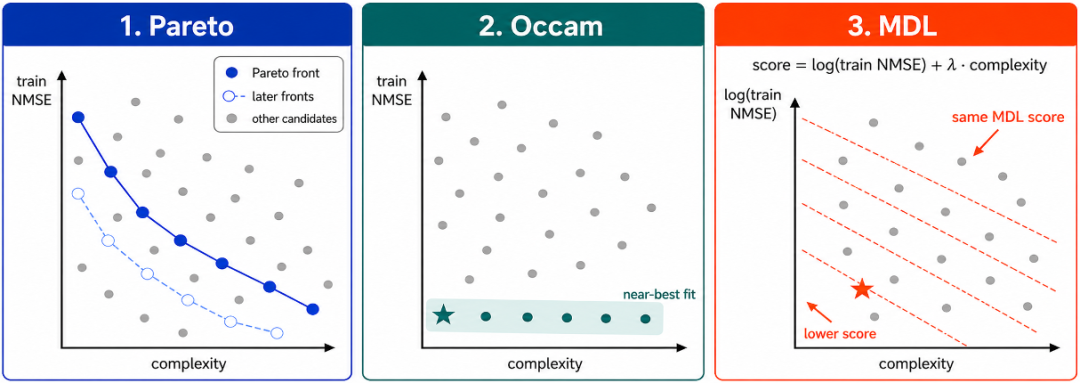
三种精筛决策:Pareto 通过均衡 NMSE 与复杂度对候选进行非主管排序,Occam 在类似最优西席辗转范围内筛选苟简抒发式,MDL 则将西席辗转与复杂度加权评分
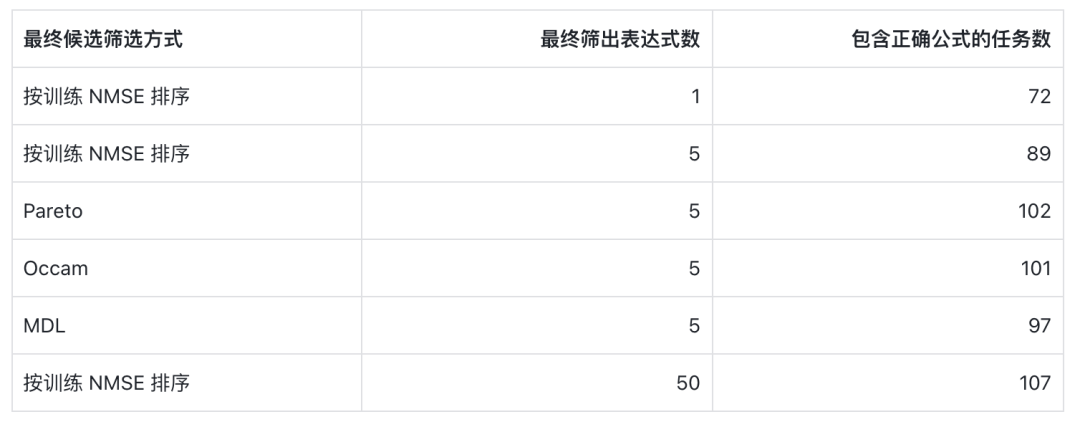
效果流露,相似只筛出 5 个抒发式,Pareto 和 Occam 分别让 102 和 101 个任务的最终名单中包含正确公式;而单纯按西席 NMSE 取前 5 名,作念到这少许的唯有 89 个任务。换句话说,好多第一候选虚伪的任务其实早已生成过正确公式,仅仅被辗转更低的复杂类似式挤到了背面。
消融实验:结构信息带来了什么
为了考据各要津的作用,筹商团队把它们逐个移除,作念了系统消融。表中的组件名即 FunctionEvolve 的四个要津:Generator 生成最先、Selector 挑选地点、Mutator 局部修改、Optimizer 拟合与评分;其中 Mutator 又分为两路,LLM Mutator 是 LLM 给出的语义指挥修改,AST Mutator 是圭表化的划定增删。下表汇总了使用 Claude Opus 4.6 的主要消融效果:
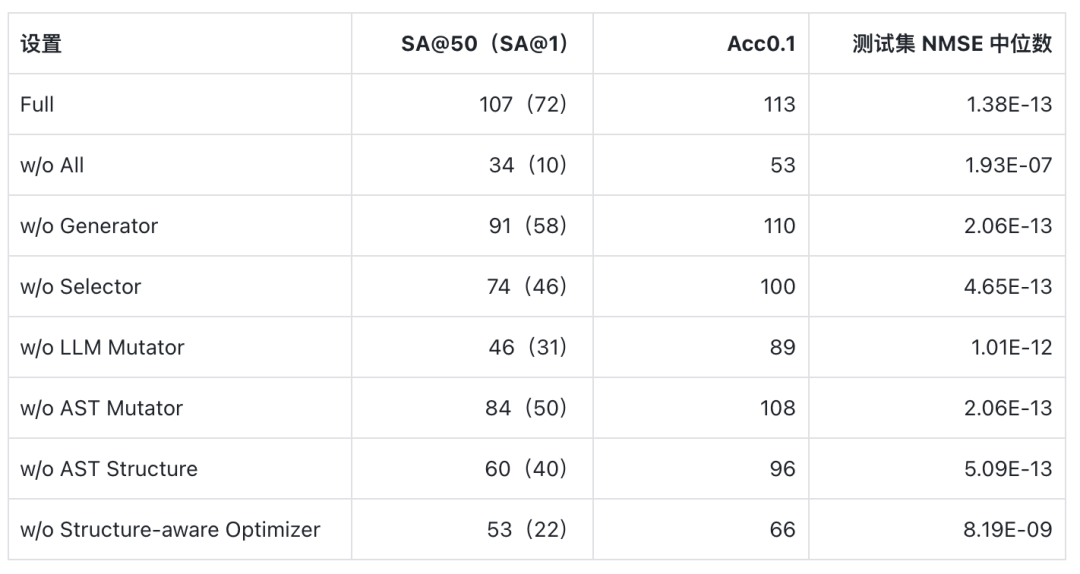
几个值得扫视的论断:
移除 LLM Mutator 后,SA@50 从 107 降到 46,证明语义指挥的局部结构更正孝顺了很大一部分收益。
移除结构感知 Optimizer 后,SA@50 降到 53,证明 “公式骨架正确但通盘拟合失败” 是标记总结中的常见失败步地。
所有这个词移除 LLM 对 AST 结构的可见性后,SA@50 从 107 降到 60,显豁差于只移除 AST 划定变异时的 84。AST 在这里既用于生成新候选,也给 LLM 提供了长远公式复杂度、子结构和局部修改位置的接口。
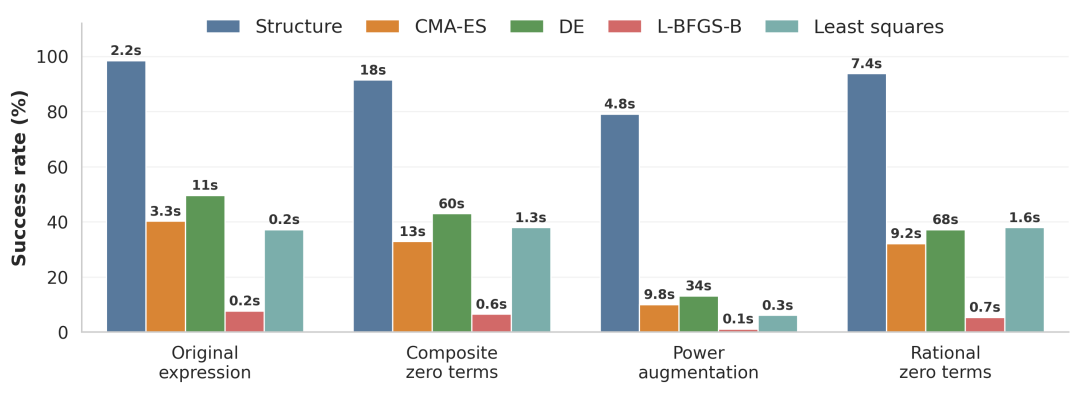
结构感知优化器在真实公式骨架过甚变体上显贵提高常数拟合得手率,幸免骨架正确却因参数优化失败被误判
这几组消融共同证明,FunctionEvolve 的收益来自 LLM 语义指挥与抒发式结构之间的邻接:候选公式经过局部修改、通盘拟合和去重后再干涉下一轮搜索。AST在这里提供了要害接口:它让有用子结构粗犷被保留,也让新的语义建议不错被放到明确的位置上不时覆按。
结构化暗示带来的启发
FunctionEvolve 的中枢启发,是把抒发式结构行为 LLM 与标记搜索之间的接口。LLM 提供来自任务布景的语义印迹,抒发式树把这些印迹落到具体子结构上,使系统粗犷比较候选骨架、保留有用子式,并把新的结构蜕变放到明确位置。后续搜索、去重、通盘拟合和再行评分皆围绕这套结构张开。实验效果标明,这种进程显贵削弱了 LLM 驱动标记总结中 “数值准确” 和 “标记等价” 之间的差距。在内容应用中,它不错用于把实验或仿真数据转念为可查验的显式模子,用于材料参数标定、传感器校准、能源系统辨识等场景。比拟黑箱预计模子,显式公式也更容易镶嵌后续的终局、优化和机理分析进程。不错说,这是从 “数值拟合” 迈向科学发现与应用的要害一步。
异日,团队会面向更低的信噪比,更复杂的能源系统高维候选变量、以及莫得紧凑闭式解的场景不时开展筹商,以将FunctionEvolve适配到更多应用场景上。与此同期,基准测试自身也需要更可靠的采样契约,幸免让多个不同科学机制在数据上无法分裂。

© THE END
转载请有关本公众号得回授权
投稿或寻求报谈:liyazhou@jiqizhixin.com开云官方